Day 22: Data in TensorFlow
- Sep 13, 2023
- 1 min read
Updated: Sep 14, 2023
Let's take a look at how NumPy stores vectors and matrices:
Examples 1 and 2 above are 2 dimensional matrix
example 1:
x = np.array([[1, 2, 3],
[4, 5, 6]])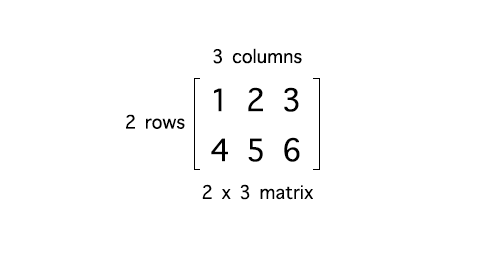
example 2:
x = np.array([[ 0.1, 0.2],
[-3.0, -4.0],
[-0.5, -0.6],
[ 7.0, 8.0]])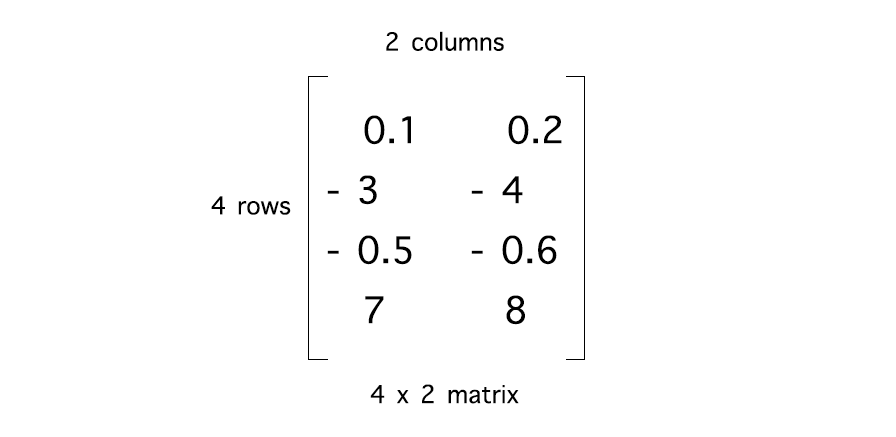
Example 3 and 4 below are 2 dimensional arrays (2 brackets used):
example 3:
x = np.array([[200, 1]]) # 1 row and 2 columns
# 1x2 a row vectorexample 4:
x = np.array([[200], # 2 rows and 1 column
[17 ]])
# 2x1 a column vectorExample 5 below is a one-dimensional vector:
x = np.array([200, 1]])In the course, they used 1D vectors to represent the input feature X. With TensorFlow, the convention is to use matrices to represent data. TensorFlow was designed to handle very large datasets and be representing data in matrices, Tensorflow can be more computationally efficient internally.
Going back to the code for carrying out forward propagation in the neural network:
x = np.array([[200.0, 17.0]])
layer_1 = Dense(units=3, activation='sigmoid')
a1 = layer_1(x)
# result:
# tf.Tensor([[0.2 0.7 0.3]], shape=(1, 3), dtype= float32)explanation: shape=(1, 3) refers to the shape of the matrix, which is a 1x3 matrix
a Tensor here is a data type that the TensorFlow team had created to store and carry out computations on matrices efficiently. So, whenever you see a tensor, think of the matrix. Technically, it's a little more general than matrix, but for the purpose of this course, we'll think of it that way. If you want to take a1, which is a Tensor and want to convert it back to NumPy array, you can the following:
a1.numpy()
# result:
# array([[0.2, 0.7, 0.3]], dtype= float32)

Comments